基本原理
cgroup是Linux内核的一个特性,主要用来对共享资源进行隔离、限制、审计等。通过cgroup可以将定额的资源分配给特定的一组进程。
默认情况下,编译内核时打开cgroup的系统中所有进程位于同一个cgroup,就是根,这个cgroup享有所有的系统资源。
可以通过cgroup文件系统建立一个新的cgroup,然后配置这个新的cgroup,配置的内容包括为其分配进程、分配资源等。这个创建和分配的所有过程都是cgroup文件系统通过shell echo写进文件完成的。
cgroup本身是分层的,一个根层下面就像一棵树一样可以分很多层。每一层的cgroup文件系统目录下都有该层对应的资源配置文件。这些可以配置的资源都是cgroup子系统。
子系统(subsystem)实际上是cgroup对进程组进行资源控制的具体体现。子系统具有多种类型,每个类型的子系统都代表一种系统资源,比如CPU、memory等。当创建一个cgroup实例时,必须至少指定一种子系统。也就是说,这个新建的进程组在访问子系统对应的系统资源时就有了一些限制。具体的限制项与子系统的类型有关。
cgroup中进程组的层级关系与Linux中进程的层级关系比较类似。在Linux操作系统中,一个进程通过fork()系统调用创建了一个子进程,这两个进程之间存在父子这样的等级关系,并且子进程可以继承父进程的一些资源。系统中所有的进程形成一个树形的等级关系,每个进程都唯一的位于进程树中的某一个位置。
对于cgroup来说,cgroup实例之间也是有具体级别关系的,但是它们层级关系是为了更细粒度的对进程组进行资源控制。同时,子cgroup会继承父cgroup的对资源的控制属性。
子系统与层级关系
一个子系统就是一个资源控制器。cgroup九个子系统分别是:
cpu子系统,主要限制进程的 cpu 使用率。cpuacct子系统,可以统计 cgroup 中的进程的 cpu 使用报告。cpuset子系统,可以为 cgroup 中的进程分配单独的 cpu 节点或者内存节点。memory子系统,可以限制进程的 memory 使用量。blkio子系统,可以限制进程的块设备 io。devices子系统,可以控制进程能够访问某些设备。net_cls子系统,可以标记 cgroup 中进程的网络数据包,然后可以使用tc 模块(traffic control)对数据包进行控制。freezer子系统,可以挂起或者恢复 cgroup 中的进程。ns子系统,可以使不同 cgroup 下面的进程使用不同的 namespace。
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroup 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroup 层级结构。
cgroup层级结构可以 attach 一个或者几个 cgroup子系统,当前层级结构可以对其 attach 的 cgroup 子系统进行资源的限制。每一个 cgroup子系统只能被attach到一个 cpu 层级结构中。
当建立第一个cgroup时,系统会把所有的进程都放进去,对应树形结构的树根,例如cat /sys/fs/cgroup/cpu/task会输出所有进程的pid。
如果在下级cgroup,例如/cgroup/test的task中将一个进程的PID echo到文件,就会发现这个进程并没有从上层cgroup的task列表中消失 ,而是同时出现在了下层test cgroup的task文件中,这就表示该进程现在归test cgroup控制。但由于test cgroup是下层 cgroup ,所以进程依然存在于上cgroup,而同层的 cgroup 之间却不能含有相同的进程。
示例:
下图时一个cgroup结构图,包含两个层级,即第一层级cpu_mem和第二层级cpuset_net。
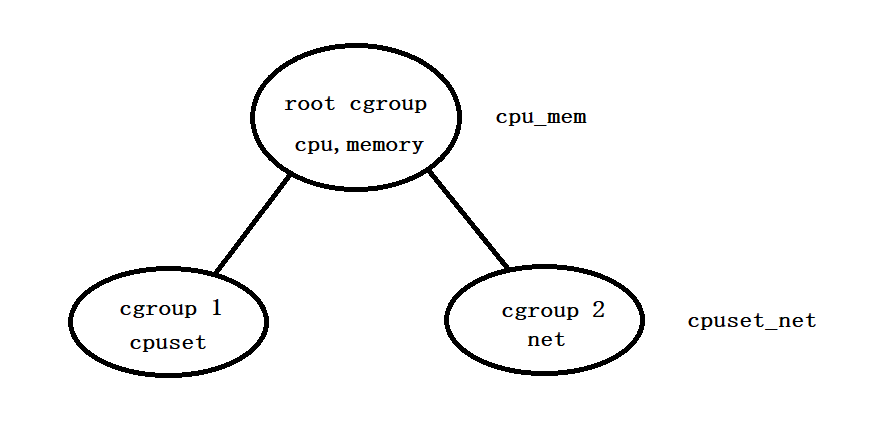
- 系统中第一个被创建的cgroup被称为
root cgroup,该cgroup的成员包含系统中所有的进程。其下又包含从cgroup1和cgroup2两个cgroup,位于第二层级cpuset_net中。 - 一个子系统只能位于一个层级中。在图中,
cpu子系统位于第一层级cpu_mem中,那么这个子系统将不能再位于第二层级中。不过第二层级会继承第一层级的cpu子系统。 - 每个层级中可以关联多个子系统。第一层级关联了
cpu和memory子系统。 - 一个进程可以位于不同层级的cgroup中。由于
root cgroup包含了系统中所有的进程,因此cgroup2中的进程P也位于root cgroup中。从资源控制角度来说,进程P所在的进程组在访问cpu、memory和net时会受到资源限制。 - 一个进程创建了子进程后,该子进程默认为父进程所在的cgroup的成员。
在创建了 cgroup 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroup 层级结构的节点中,因为不同的 cgroup 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
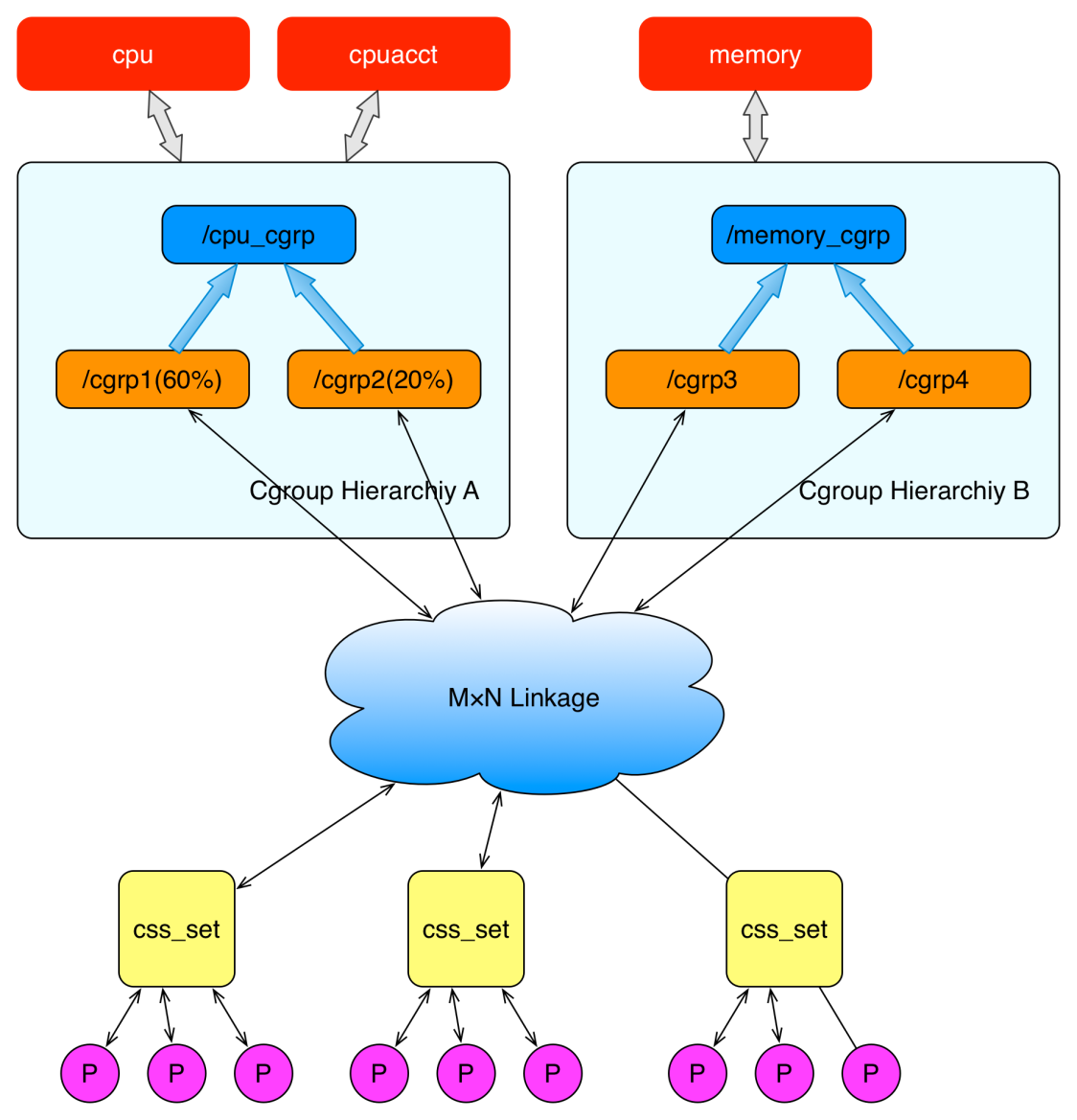
上面这个图从整体结构上描述了进程与 cgroup 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroup subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的"M×N Linkage"说明的是css_set通过辅助数据结构可以与 cgroup 节点进行多对多的关联。但是 cgroup 的实现不允许css_set同时关联同一个cgroup层级结构下多个节点。 这是因为 cgroup 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroup 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroup 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
VFS文件系统
cgroup需要提供接口给用户态,有两个选择,一个是提供系统调用,另一个是提供虚拟文件系统。cgroup选择个后者,它提供了一种名为cgroup的文件系统。
VFS(Virtual File System) 是一个内核抽象层,能够隐藏具体文件系统的实现细节,从而给用户态进程提供一套统一的 API 接口。
VFS 使用了一种通用文件系统的设计,具体的文件系统只要实现了 VFS 的设计接口,就能够注册到 VFS 中,从而使内核可以读写这种文件系统。
这很像面向对象设计中的抽象类与子类之间的关系,抽象类负责对外接口的设计,子类负责具体的实现。其实,VFS本身就是用 c 语言实现的一套面向对象的接口。
cgroup通过VFS向用户层提供接口,用户通过挂载,创建目录,读写文件的方式与cgroup交互。
通用文件模型
VFS 通用文件模型中包含以下四种元数据结构:
- 超级块对象(superblock object),用于存放已经注册的文件系统的信息。比如ext2,ext3等这些基础的磁盘文件系统,还有用于读写socket的socket文件系统,以及当前的用于读写cgroup配置信息的 cgroup 文件系统等。
- 索引节点对象(inode object),用于存放具体文件的信息。对于一般的磁盘文件系统而言,inode 节点中一般会存放文件在硬盘中的存储块等信息;对于socket文件系统,inode会存放socket的相关属性,而对于cgroup这样的特殊文件系统,inode会存放与 cgroup 节点相关的属性信息。这里面比较重要的一个部分是一个叫做 inode_operations 的结构体,这个结构体定义了在具体文件系统中创建文件,删除文件等的具体实现。
- 文件对象(file object),一个文件对象表示进程内打开的一个文件,文件对象是存放在进程的文件描述符表里面的。同样这个文件中比较重要的部分是一个叫 file_operations 的结构体,这个结构体描述了具体的文件系统的读写实现。当进程在某一个文件描述符上调用读写操作时,实际调用的是 file_operations 中定义的方法。 对于普通的磁盘文件系统,file_operations 中定义的就是普通的块设备读写操作;对于socket文件系统,file_operations 中定义的就是 socket 对应的 send/recv 等操作;而对于cgroup这样的特殊文件系统,file_operations 中定义的就是操作 cgroup 结构体等具体的实现。
- 目录项对象(dentry object),在每个文件系统中,内核在查找某一个路径中的文件时,会为内核路径上的每一个分量都生成一个目录项对象,通过目录项对象能够找到对应的 inode 对象,目录项对象一般会被缓存,从而提高内核查找速度。
cgroup文件系统的实现
基于VFS实现的文件系统,都必须实现VFS通用文件模型定义的这些对象,并实现这些对象定义的部分函数。cgroup文件系统也不例外。
cgroup文件系统类型的结构体:
static struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
};
这里面两个函数分别代表安装和卸载某一个 cgroup 文件系统所需要执行的函数。每次把某一个 cgroup 子系统安装到某一个装载点的时候,cgroup_mount 方法就会被调用,这个方法会生成一个 cgroup_root(cgroup层级结构的根)并封装成超级快对象。
cgroup超级块对象定义的操作:
static const struct super_operations cgroup_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.show_options = cgroup_show_options,
.remount_fs = cgroup_remount,
};
这里只有部分函数的实现,这是因为对于特定的文件系统而言,所支持的操作可能仅是 super_operations 中所定义操作的一个子集,比如说对于块设备上的文件对象,肯定是支持类似 fseek 的查找某个位置的操作,但是对于 socket 或者 cgroup 这样特殊的文件系统,就不支持这样的操作。
inode对象和file对象的定义的特殊实现函数:
static const struct inode_operations cgroup_dir_inode_operations = {
.lookup = cgroup_lookup,
.mkdir = cgroup_mkdir,
.rmdir = cgroup_rmdir,
.rename = cgroup_rename,
};
static const struct file_operations cgroup_file_operations = {
.read = cgroup_file_read,
.write = cgroup_file_write,
.llseek = generic_file_llseek,
.open = cgroup_file_open,
.release = cgroup_file_release,
};
从这些代码可以推断出,cgroup 通过实现 VFS 的通用文件系统模型,把维护 cgroup 层级结构的细节,隐藏在 cgroup 文件系统的这些实现函数中。
从另一个方面说,用户在用户态对 cgroup 文件系统的操作,通过 VFS 转化为对 cgroup 层级结构的维护。通过这样的方式,内核把 cgroup 的功能暴露给了用户态的进程。
简单用法及说明
挂载cgoup文件系统
和所有的文件系统一样,cgroup文件系统需要先挂载,通过mount命令挂载 cgroup 文件系统,格式为:
mount -t cgroup -o subsystems name /cgroup/name
其中-t cgroup指定文件系统类型为cgroup类型,-o subsystems 表示需要关联的cgroup子系统,可以用逗号隔开,表示同时挂载多个子系统,name表示实例的名称,/cgroup/name 表示挂载点,这条命令同时在内核中创建了一个cgroup 层级结构。(目前大多操作系统启动时已经默认挂载/sys/fs/cgroup)
比如挂载 cpuset, cpu, cpuacct, memory 4个subsystem到/cgroup/cpu_and_mem 目录下,就可以使用 mount -t cgroup -o remount,cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem。
cgroup文件系统的一个特点是用户可以同时挂载多个cgroup文件系统,但是要保证每个cgroup文件系统用到的子系统没有重叠。也就是说,如果已经有一个cgroup文件系统的挂载包含了某一个子系统,其它cgroup文件系统就不能包含这个子系统。
ubuntu和centos的做法是每个cgroup文件系统的挂载基本只包含一个子系统。
ll /sys/fs/cgroup/
total 0
drwxr-xr-x. 2 root root 0 May 25 04:19 blkio
lrwxrwxrwx. 1 root root 11 May 25 04:19 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 May 25 04:19 cpuacct -> cpu,cpuacct
drwxr-xr-x. 3 root root 0 May 25 04:19 cpu,cpuacct
drwxr-xr-x. 2 root root 0 May 25 04:19 cpuset
drwxr-xr-x. 2 root root 0 May 25 04:19 devices
drwxr-xr-x. 2 root root 0 May 25 04:19 freezer
drwxr-xr-x. 2 root root 0 May 25 04:19 hugetlb
drwxr-xr-x. 2 root root 0 May 25 04:19 memory
lrwxrwxrwx. 1 root root 16 May 25 04:19 net_cls -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 May 25 04:19 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 May 25 04:19 net_prio -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 May 25 04:19 perf_event
drwxr-xr-x. 2 root root 0 May 25 04:19 pids
drwxr-xr-x. 4 root root 0 May 25 04:19 systemd
以CPU子系统所在的cgroup文件系统为例:
ll /sys/fs/cgroup/cpu/
total 0
-rw-r--r--. 1 root root 0 May 25 04:19 cgroup.clone_children
--w--w--w-. 1 root root 0 May 25 04:19 cgroup.event_control
-rw-r--r--. 1 root root 0 May 25 04:19 cgroup.procs
-r--r--r--. 1 root root 0 May 25 04:19 cgroup.sane_behavior
-r--r--r--. 1 root root 0 May 25 04:19 cpuacct.stat
-rw-r--r--. 1 root root 0 May 25 04:19 cpuacct.usage
-r--r--r--. 1 root root 0 May 25 04:19 cpuacct.usage_percpu
drwxr-xr-x. 3 root root 0 May 25 04:52 cpu_c1
-rw-r--r--. 1 root root 0 May 25 04:19 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 May 25 04:19 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 May 25 04:19 cpu.rt_period_us
-rw-r--r--. 1 root root 0 May 25 04:19 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 May 25 04:19 cpu.shares
-r--r--r--. 1 root root 0 May 25 04:19 cpu.stat
-rw-r--r--. 1 root root 0 May 25 04:19 notify_on_release
-rw-r--r--. 1 root root 0 May 25 04:19 release_agent
-rw-r--r--. 1 root root 0 May 25 04:19 tasks
总共包含的文件可以分为三类:
- 目录。再cgroup文件系统中目录对应一个具体的cgroup。
- 通用文件。以
cgroup.为前缀的文件和三个无前缀的文件notify_on_release, release_agent, tasks,这些通用文件再每个cgroup文件系统都会出现,无论指定的是哪个子系统。 - 子系统专有文件。这些文件是配置子系统的接口,子系统不同,文件也不同。例如上面的以
cpu.为前缀的文件。
在cgroup文件系统中,创建(删除)一个目录就是创建(删除)一个cgroup,创建完目录后,会自动产生很多文件,在cgroup文件系统的根目录下(在上面的例子中是/sys/fs/cgroup/cpu)的大多数文件都会出现在cgroup文件系统的下级目录中,除了少数在代码实现中标记为只在根目录中出现的文件,例如cgroup.sane_behavior。
各个子系统的通用文件:
cgroup.procs
此文件的内容和cgroup中所有进程的进程号关联。这里的进程号实际上是线程组号(thread group ID)。向这个文件写入一个线程组号,就会把整个线程组中的线程都加入此文件所属的cgroup。cgroup.clone_chidren
这个文件和一个标志关联,而此标志只被cpuset子系统使用。当此标志为1时,创建新的有关cpuset的cgroup时,子cgroup从父cgroup中复制cpuset配置。cgroup.sane_behavior
显示cgroup文件系统的sane_behavior的状态。随着内核控制组子系统的开发,一些旧的做法不再合适,但是为了兼容旧的应用又不好完全清除。于是开发者提供了一个选项__DEVEL__sane_behavior,供挂载时使用。如果有这个挂载选项,老旧的不合适的代码逻辑就不会出现,tasks、notify_on_release、release_agent这三个文件也不会出现。tasks
旧机制,尽量不要使用。此文件关联控制组中所有线程的线程号。notify_on_release
旧机制,尽量不要使用。通过它来存取notify_on_release标志。当此标志为 1 时,在 cgroup退出时,内核要通知用户态。所谓退出是指此 cgroup 不再有进程,也不再有子 cgroup。release_agent
旧机制,尽量不要使用。此文件中存有一个路径,当内核需要通知用户态 cgroup 退出事件时,内核运行此路径所指的可执行文件。
子节点和进程
挂载某一个cgroup子系统到挂载点之后,就可以通过在挂载点下面建立文件夹创建cgroup层级结构中的节点,当创建完文件夹后,会自动在其中创建相关的配置文件。创建目录的动作也就是创建了下个层级的一个分支,还可以在这个目录中继续创建目录,形成第三层级。
然后在相应的配置文件中写上具体的配置。例如在cpu.shares中写入整数值可以控制该cgroup获得的时间片。
创建并配置完节点后,将进程的pid写入子节点下面的task文件中即可。
示例:
# 在cpu层级创建一个新的cgroup节点
# 命名为cpu_c1
mkdir /cgroup/cpu/cpu_c1
# 设置`cpu.shares`文件
# 将cpu_c1目录下的cpu.shares文件值设为2048,这样在系统出现cpu争抢时
# 属于cpu_c1这个cgroup的进程占用资源是其它进程的2倍。
echo 2048 >> /cgroup/cpu/cpu_c1/cpu.shares
# 将进程加入到`cpu_c1`这个cgroup节点。
echo pid >> /cgroup/cpu/cpu_c1/tasks
查看已经挂载的cgroup
mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroup-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
源码分析
cgroup分为三个部分:
- 描述子系统(subsys)和cgroup等对象、和它们的依附关系等数据结构;
- 提供给用户空间的文件系统接口;
- 各子系统。
数据结构
任务(task)
task对应linux中的进程,task和cgroup之间是多对多的关系,cgroup和subsys是一对多的关系,task和subsys也是多对多的关系(task可以依附多个cgroup,一个cgroup可能依附了多个subsys)。
要描述这些关系不容易,如果task通过各cgroup来引用各subsys再从subsys获取到资源限制,这比较低效。但是从task视角来看,每个task受到各个子系统的限制的是一定的,内核用css_set来描述多个subsys的组合,task通过css_set知道它受哪些限制,加快了访问速度,而且subsys组合是有限的,减少了内核数据结构的复杂度。
css_set
看css_set结构体,css_set表示一种资源限制的集合(比如cpu 20% mem 40%和cpu 30% mem 20%是不同的资源限制,用不同的css_set)并且连接进程和subsys。
// include/linux/cgroup.h
struct css_set {
…
// 引用此css_set的进程链表
struct list_head tasks;
// 关联的cgroup链表,通过cg_cgroup_link结构体来连接
struct list_head cgrp_links;
// cg_links用于链接所有关于此css_set的cgroup,cgroup并不是直接连接到此list_head,而是通过cg_cgroup_link结构体连接。
//用于引用到css_set里具体的subsys,每个subsys在这里都有个元素,
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
…
};
- 进程结构体
task_struct:
// include/linux/sched.h
struct task_struct {
…
#ifdef CONFIG_cgroup
// 该进程关联的css_set
struct css_set __rcu *cgroup;
// 链接到关联此css_set的task链表
struct list_head cg_list;
#endif
…
}
task可以通过task_struct->css_set->subsys->cgroup找到该task所依附的cgroup。
cgroup
在结构体cgroup中,一个cgroup实例就是cgroup文件系统中的一个cgroup文件,cgroup结构体主要作用是关联css_set和subsys。
对于task到cgroup不需要直接连接,可以通过css_set引用到cgroup。
// include/linux/cgroup.h
// 子节点cgroup
struct cgroup {
…
struct list_head sibling; /* my parent's children */
struct list_head children; /* my children */
struct cgroup *parent; /* my parent */
struct list_head files; /* my files */
struct dentry *dentry; /* cgroup fs entry, RCU protected */
struct cgroupfs_root *root; // 指向hierarchy结构体,每个cgroup文件系统都有一个cgroupfs_root,在mount时创建
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
struct list_head cset_links;
…
};
大致可以分为4部分:
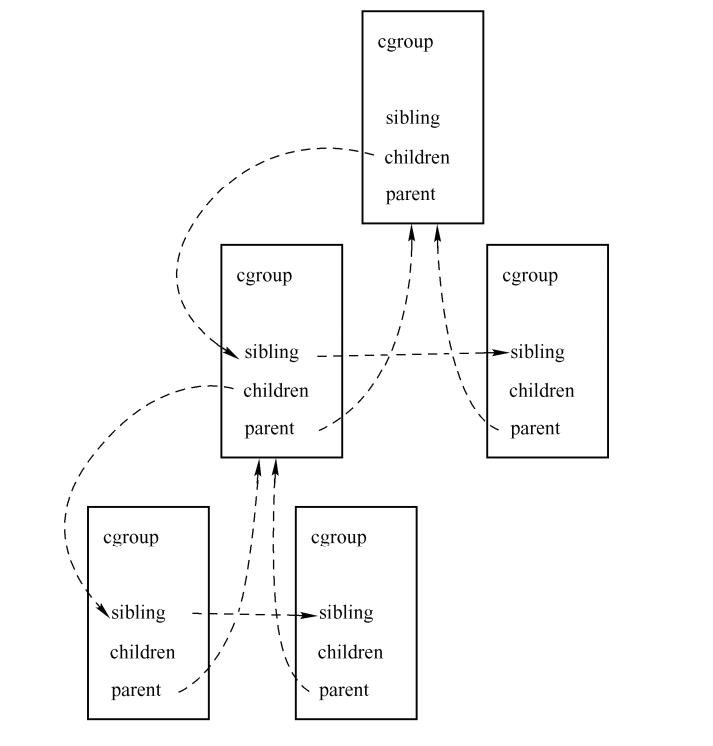
- cgroup层级结构,包括
sibling children parent三个成员;
假设存在这样一棵树,根节点有两个儿子,第一个儿子又有两个儿子。那么cgroup层级结构关系如图。
- cgroup和文件系统的关系,包括
files dentry root三个成员;
内核cgroup子系统创造了名为cgroup的虚拟文件系统。每个cgroup节点都和此文件系统中的一个目录相联系。
结构体中成员dentry *dentry指向与之相关联的目录,成员list_head files指向目录下的文件,成员cgroupfs_root*root指向cgroup文件系统的根节点。
一个cgroup实例是属于一个层级的,而一个层级有专门的结构体描述,如同文件系统有个super_block超级块一样。
// include/linux/cgroup.h
struct cgroupfs_root {
…
struct super_block *sb; // 这个层级相关联的文件系统的super_block
unsigned long subsys_mask; // 表示这个cgroup文件系统挂载中包含的子系统
struct cgroup top_cgroup; // 根目录所关联的cgroup
int number_of_cgroup; // 表示此层级中包含的cgroup的数量
…
};
控制组定义了一个新的文件系统,名为cgroup:
// kernel/cgroup.c
static struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
};
示例:
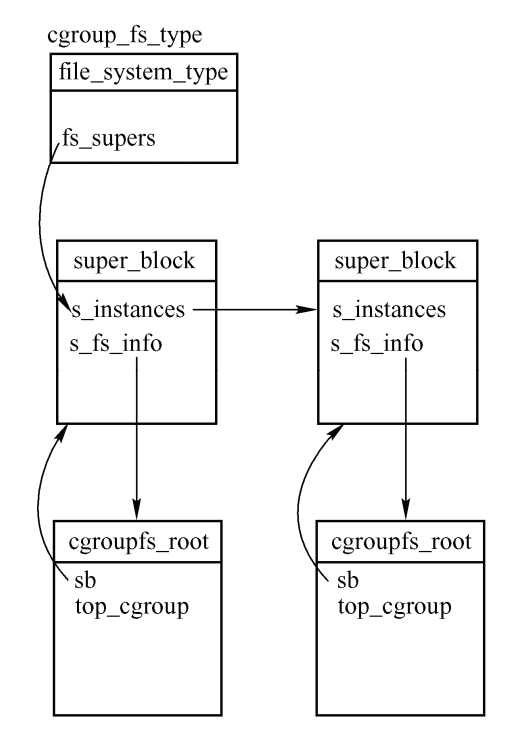
mount -t cgroup cgroup -o cpu /sys/fs/cgroup/cpu
mount -t cgroup cgroup -o memory /sys/fs/cgroup/memory
这两条命令挂载了两个cgroup文件系统,一个使用CPU子系统,一个使用memory子系统、内核中的数据结构如图。
- cgroup子系统,成员为
subsys;
首先先看cgroup_subsys:
cgroup_subsys
cgroup_subsys描述一个subsys,内核中的subsys在代码里定义好了,不存在动态添加subsys。所有subsys存在数组subsys中,其数组元素声明在linux/cgroup_subsys.h中,而实际每个元素是定义在各个子系统的文件中,比如mem_cgroup的子系统mem_cgroup_subsys是定义在mm\memcontrol.c中。
...
static struct cgroup_subsys *subsys[CGROUP_SUBSYS_COUNT] = {
#include <linux/cgroup_subsys.h>
};
struct cgroup_subsys {
struct cgroup_subsys_state *(*css_alloc)(struct cgroup_subsys_state *parent_css);
int (*css_online)(struct cgroup_subsys_state *css);
void (*css_offline)(struct cgroup_subsys_state *css);
void (*css_free)(struct cgroup_subsys_state *css);
int (*css_attach)(struct cgroup_subsys_state *css, struct cgroup_taskset *tset);
void (*cancel_attach)(struct cgroup_subsys_state *css, struct cgroup_taskset *tset);
void (*attach)(struct cgroup_subsys_state *css, struct cgroup_taskset *tset);
void (*fork)(struct cgroup_subsys_state *css, struct cgroup_taskset *tset);
void (*fork)(struct task_struct *task);
void (*exit)(struct cgroup_subsys_state *css, struct cgroup_subsys_state
*old_css, struct task_struct *task);
void (*bind)(struct cgroup_subsys_state *root_css);
…
struct list_head cftsets;
struct cftype *base_cftypes;
struct cftype_set base_cftset;
}
每个subsys有自己的属性和操作,用相同的结构体来描述subys有点太困难了,cgroup_subsys描述的是subsys通用的部分,各种不同的subsys(如mem_cgroup,cpu等)是有自己的结构体的。
cgroup_subsys的字段主要可以分为三部分:
- 回调函数指针变量;
- 用于
cgroup_subsys组织结构; - 一部分和cftype相关,每个cgroup目录下都有一些subsys的文件用于设置subsys的属性,这些属性是cftype描述的。
回调函数
回调函数中css_alloc值得关注,该函数创建具体subsys的结构体并返回一个cgroup_subsys_state,该结构体的指针是css_set->subsys数组的元素。mem_cgroup_subsys的css_alloc函数mem_cgroup_css_alloc。
static struct cgroup_subsys_state * __ref
mem_cgroup_css_alloc(struct cgroup *cont)
{
struct mem_cgroup *memcg;
long error = -ENOMEM;
int node;
memcg = mem_cgroup_alloc();
if (!memcg)
return ERR_PTR(error);
for_each_node(node)
if (alloc_mem_cgroup_per_zone_info(memcg, node))
goto free_out;
/* root ? */
if (cont->parent == NULL) {
root_mem_cgroup = memcg;
page_counter_init(&memcg->memory, NULL);
memcg->soft_limit = PAGE_COUNTER_MAX;
page_counter_init(&memcg->memsw, NULL);
page_counter_init(&memcg->kmem, NULL);
}
memcg->last_scanned_node = MAX_NUMNODES;
INIT_LIST_HEAD(&memcg->oom_notify);
atomic_set(&memcg->refcnt, 1);
memcg->move_charge_at_immigrate = 0;
mutex_init(&memcg->thresholds_lock);
spin_lock_init(&memcg->move_lock);
vmpressure_init(&memcg->vmpressure);
return &memcg->css;
free_out:
__mem_cgroup_free(memcg);
return ERR_PTR(error);
}
struct mem_cgroup {
struct cgroup_subsys_state css;
...
}
组织结构
不同子系统的结构体第一个元素都是cgroup_subsys_state以便于使用container_of。以mem_cgroup子系统为例,mem_cgroup子系统的结构体是mem_cgroup,每个css_set都可以container_of css_set->subsys[mem_cgroup_subsys_id]引用到一个mem_cgroup实例。相对于mem_cgroup结构体,cgroup_subsys用于全局描述一个subsys。
cftype
在cgroup文件系统中,每个目录下有各个子系统的文件,而不同子系统的文件是不一样的,内核里通过cftype结构体来描述这些文件。
cftype这个结构体里主要是一些文件操作函数和文件的描述信息。所有对文件的操作,都会调用这个结构体中的操作函数。每个subsys在cgroup_subsys->base_cftypes中定义自己专有的文件。而cgroup每个目录下都有些相同的文件像tasks之类的,保存在cgroup.c中的files数组中,这时每个目录都会有的。
struct cftype {
/*
* By convention, the name should begin with the name of the
* subsystem, followed by a period. Zero length string indicates
* end of cftype array.
*/
char name[MAX_CFTYPE_NAME];
int private;
/*
* If not 0, file mode is set to this value, otherwise it will
* be figured out automatically
*/
umode_t mode;
/*
* If non-zero, defines the maximum length of string that can
* be passed to write_string; defaults to 64
*/
size_t max_write_len;
/* CFTYPE_* flags */
unsigned int flags;
int (*open)(struct inode *inode, struct file *file);
...
例如CPU子系统:
// kernel/sched/core.c
static struct cftype cpu_files[] = {
#ifdef CONFIG_FAIR_GROUP_SCHED
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
#endif
#ifdef CONFIG_CFS_BANDWIDTH
{
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
},
{
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
},
{
.name = "stat",
.seq_show = cpu_stats_show,
},
#endif
#ifdef CONFIG_RT_GROUP_SCHED
{
.name = "rt_runtime_us",
.read_s64 = cpu_rt_runtime_read,
.write_s64 = cpu_rt_runtime_write,
},
{
.name = "rt_period_us",
.read_u64 = cpu_rt_period_read_uint,
.write_u64 = cpu_rt_period_write_uint,
},
#endif
};
cgroup_subsys_state
结构体cgroup_subsys_state是一个"中介",介于结构体cgroup和结构体cgroup_subsys之间。
css_set有一个cgroup_subsys_state指针数组,共CGROUP_SUBSYS_COUNT个元素,意味这每个subsys在其中都有个cgroup_subsys_state实例结构体,但这个结构体里并没有包含实际控制信息。那具体控制信息在哪呢?cgroup_subsys_state实际是和kobjecct类似作用的东西,里面包含了各个subsys共有的信息。通过container_of获取的到subsys直接的实例结构体,subsys的私有控制信息都在该实际结构体中。
// include/linux/cgroup.h
struct cgroup_subsys_state {
// 本subsys所依附的cgroup
struct cgroup *cgroup;
// 用到的子系统
struct cgroup_subsys *ss;
...
}
- cgroup和进程的关系,成员为
cset_links。
cgroup节点和进程是多对多映射。一个cgrou节点中可以有多个进程,一个进程也可以加入多个cgroup。
假设有 3 个进程,4 个控制组,进程 1 用到控制组 1 和 3,进程 2 用到控制组 2 和 4,进程 3 用到控制组 2 和 4。从进程的角度看和从控制组的角度看,如图所示。
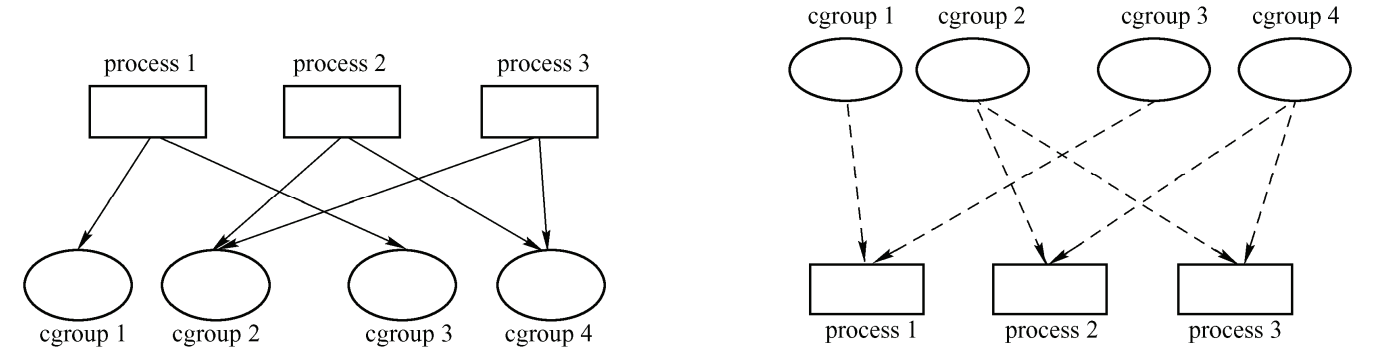
在结构cgroup中有:
// include/linux/cgroup.h
struct cgroup {
…
struct list_head cset_links;
…
}
结构 cgroup 的成员 cset_links 和另一个结构 cgrp_cset_link 关联:
kernel/cgroup.c
struct cgrp_cset_link {
/* the cgroup and css_set this link associates */
struct cgroup *cgrp;
struct css_set *cset;
/* list of cgrp_cset_links anchored at cgrp->cset_links */
struct list_head cset_link;
/* list of cgrp_cset_links anchored at css_set->cgrp_links */
struct list_head cgrp_link;
};
联系在一起,还是上面那个例子,内核中的数据结构如图所示。
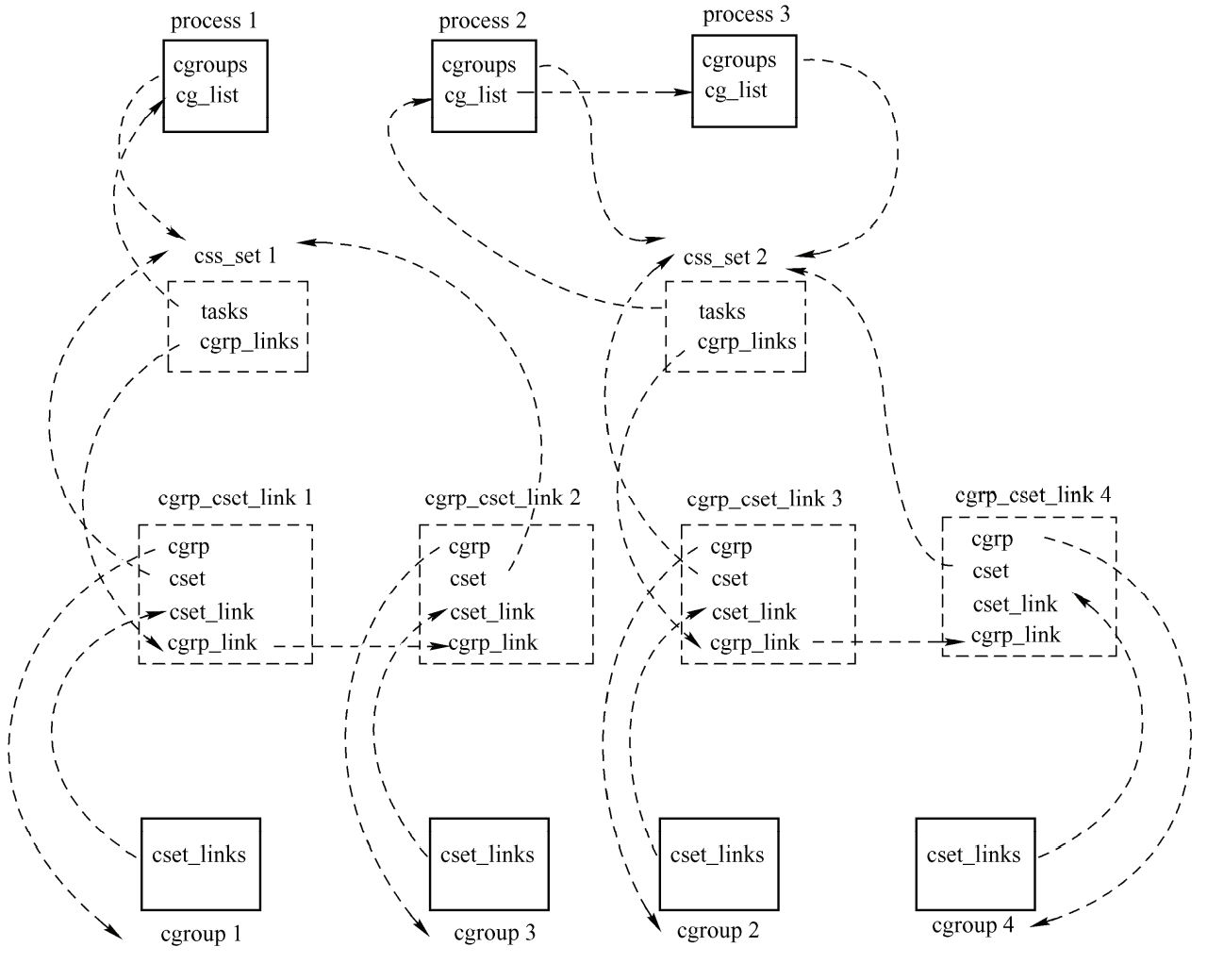
cgroup_root和cgroup是使用两个不同结构表示的。
文件系统接口
cgroup文件系统是cgroup提供给用户层的控制接口,cgroup文件系统挂不挂载,cgroup都是生效运行的。
mount函数
static struct dentry *cgroup_mount(struct file_system_type *fs_type,
int flags, const char *unused_dev_name,
void *data)
{
struct cgroup_sb_opts opts;
struct cgroupfs_root *root;
int ret = 0;
struct super_block *sb;
struct cgroupfs_root *new_root;
struct inode *inode;
/* First find the desired set of subsystems */
mutex_lock(&cgroup_mutex);
ret = parse_cgroupfs_options(data, &opts);//解析挂载参数,看需要attach哪些subsys
mutex_unlock(&cgroup_mutex);
if (ret)
goto out_err;
/*
* Allocate a new cgroup root. We may not need it if we're
* reusing an existing hierarchy.
*/
new_root = cgroup_root_from_opts(&opts);//依据挂载参数创建一个新的cgroupfs_root,后面如果有发现已申请了相同的会free掉这个结构体
if (IS_ERR(new_root)) {
ret = PTR_ERR(new_root);
goto drop_modules;
}
opts.new_root = new_root;
/* Locate an existing or new sb for this hierarchy */
//获取sb这个文件系统的sb
sb = sget(fs_type, cgroup_test_super, cgroup_set_super, 0, &opts);
if (IS_ERR(sb)) {
ret = PTR_ERR(sb);
cgroup_drop_root(opts.new_root);
goto drop_modules;
}
root = sb->s_fs_info;
BUG_ON(!root);
if (root == opts.new_root) {//未挂载相同参数的cgroup fs
/* We used the new root structure, so this is a new hierarchy */
struct list_head tmp_cg_links;
struct cgroup *root_cgrp = &root->top_cgroup;
struct cgroupfs_root *existing_root;
const struct cred *cred;
int i;
struct css_set *cg;
BUG_ON(sb->s_root != NULL);
ret = cgroup_get_rootdir(sb);
if (ret)
goto drop_new_super;
inode = sb->s_root->d_inode;
mutex_lock(&inode->i_mutex);
mutex_lock(&cgroup_mutex);
mutex_lock(&cgroup_root_mutex);
/* Check for name clashes with existing mounts */
ret = -EBUSY;
if (strlen(root->name))
for_each_active_root(existing_root)
if (!strcmp(existing_root->name, root->name))
goto unlock_drop;
/*
* We're accessing css_set_count without locking
* css_set_lock here, but that's OK - it can only be
* increased by someone holding cgroup_lock, and
* that's us. The worst that can happen is that we
* have some link structures left over
*/
//css_set_count是内核中已有css_set的个数
ret = allocate_cg_links(css_set_count, &tmp_cg_links);
if (ret)
goto unlock_drop;
//将subsys_mask指示的subsys绑定到当前cgroupfs_root
ret = rebind_subsystems(root, root->subsys_mask);
if (ret == -EBUSY) {
free_cg_links(&tmp_cg_links);
goto unlock_drop;
}
/*
* There must be no failure case after here, since rebinding
* takes care of subsystems' refcounts, which are explicitly
* dropped in the failure exit path.
*/
/* EBUSY should be the only error here */
BUG_ON(ret);
list_add(&root->root_list, &roots);
root_count++;
sb->s_root->d_fsdata = root_cgrp;
root->top_cgroup.dentry = sb->s_root;
/* Link the top cgroup in this hierarchy into all
* the css_set objects */
//将当前所有的css_set关联到这个root_cgrp中
write_lock(&css_set_lock);
hash_for_each(css_set_table, i, cg, hlist)
link_css_set(&tmp_cg_links, cg, root_cgrp);
write_unlock(&css_set_lock);
free_cg_links(&tmp_cg_links);
BUG_ON(!list_empty(&root_cgrp->children));
BUG_ON(root->number_of_cgroup != 1);
cred = override_creds(&init_cred);
cgroup_populate_dir(root_cgrp, true, root->subsys_mask);// 创建根目录下的文件
revert_creds(cred);
mutex_unlock(&cgroup_root_mutex);
mutex_unlock(&cgroup_mutex);
mutex_unlock(&inode->i_mutex);
} else { //已存在相同参数的文件系统
...
}
...
return ERR_PTR(ret);
}
cgroup文件系统的挂载主要是将参数所指定的subsys绑定到文件系统,并将新层级的根cgroup关联到现有的css_set中。将subsys绑定到文件系统用的是rebind_subsystems这个函数,为什么叫rebind呢?因为这个函数是将原来绑定到rootnode的subsys绑定到新的cgroupfs_root。而这里的绑定,是将subsys->root指向新的cgroupfs_root中。
各个子系统的实现
上面可以知道,内核中的cgroup机制提供一个框架,通过在其中添加子系统,可以实现对进程的不同资源进行限制。以cpuacct为例,其子系统实现在kernel/sched/cpuacct.c,这是在调度系统里添加的一个子系统,用于进程占用时间片的统计。
struct cgroup_subsys cpuacct_subsys = {
.name = "cpuacct",
.css_alloc = cpuacct_css_alloc,
.css_free = cpuacct_css_free,
.subsys_id = cpuacct_subsys_id,
.base_cftypes = files,
.early_init = 1,
};
static struct cftype files[] = {
{
.name = "usage",
.read_u64 = cpuusage_read,
.write_u64 = cpuusage_write,
},
{
.name = "usage_percpu",
.read_seq_string = cpuacct_percpu_seq_read,
},
{
.name = "stat",
.read_map = cpuacct_stats_show,
},
{ } /* terminate */
};
/* track cpu usage of a group of tasks and its child groups */
struct cpuacct {
struct cgroup_subsys_state css;
/* cpuusage holds pointer to a u64-type object on every cpu */
u64 __percpu *cpuusage;
struct kernel_cpustat __percpu *cpustat;
};
void cpuacct_charge(struct task_struct *tsk, u64 cputime)
{
struct cpuacct *ca;
int cpu;
cpu = task_cpu(tsk);
rcu_read_lock();
ca = task_ca(tsk);
while (true) {
u64 *cpuusage = per_cpu_ptr(ca->cpuusage, cpu);
*cpuusage += cputime;
ca = parent_ca(ca);
if (!ca)
break;
}
rcu_read_unlock();
}
cpuacct实现很简单,定义了cpuacct_subsys,它的属性只有三个,内嵌cgroup_subsys_state的结构体也只有两个额外的percpu变量。其运行原理是在进程调度的时候调用cpuacct_charge将进程运行时间记录到进程相关的cgroup的cpuacct子系统的结构体中。在用户读相关cgroup文件的时候将其打印出来。
总结
cgroup的组指的是一组进程。如果不做干预,进程创建的子进程会被自动加入到进程所在的控制组之中。控制组的优点是可以针对一组数量不定的进程进行控制和统计。
控制组没有增加新的系统调用,而是实现了一种新的文件系统 cgroup。有了 cgroup 文件系统,创建和删除控制组就转化为创建和删除目录,查看资源使用情况和调整参数就转化为读写文件。相比系统调用,操作文件无疑更加方便。