C++编译器GCC
C/C++常用的编译器是由GNU开发的GCC(GNU Compiler Collection)编译器。
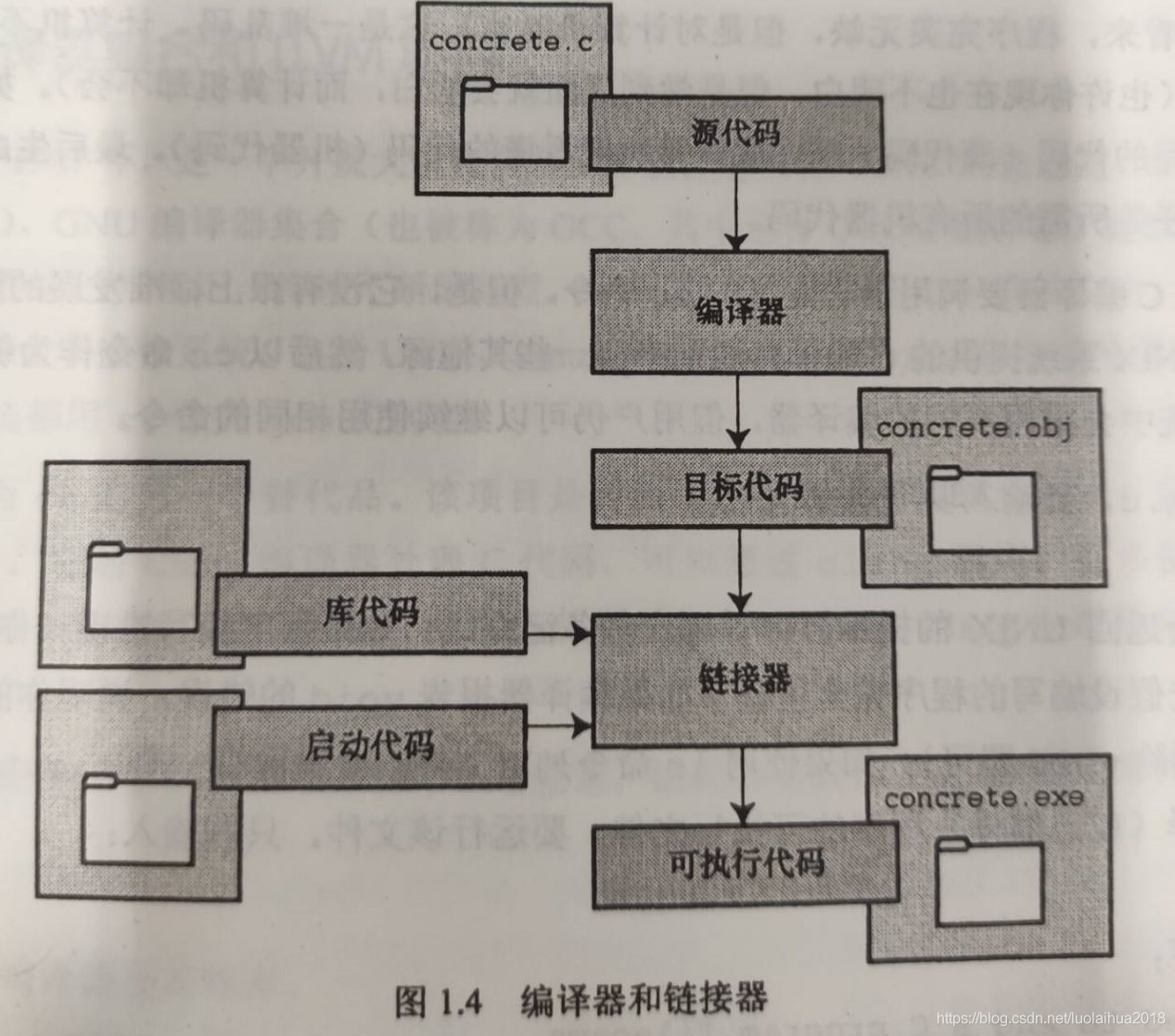
通过GCC编译器可以完成预处理、编译、优化、链接,生成可执行二进制代码。
常用命令:
gcc test.c -o test
编译过程
C/C++预处理、编译、汇编、链接共需4个步骤转换为可执行程序。
.c --(预处理)--> .i --(编译)--> .s --(汇编)--> .o --(链接)--> 可执行程序
- 预处理:将宏定义
#define、条件编译指令#ifdef/#ifndef/#endif、导入#include等进行替换和导入,删除注释,添加行号、文件标识符,保留#pragma编译器指令(.i); - 编译:编译是对代码进行词法语法分析和优化产生汇编代码(.s);
- 汇编:汇编是将汇编指令转换成机器可以识别的二进制机器指令文件(.o)。
- 链接:链接就是把编写的目标代码(.o文件)和系统标准启动代码、库代码这三部分合并成一个文件,即可执行文件,分为静态链接和动态链接。静态链接是在编译阶段就把静态库加入到可执行文件中去,这样可执行文件在执行时就不需要在链接库文件,但可执行文件就比较大;动态链接在链接阶段只加入一些描述信息,而程序执行时再把相应动态库加载到内存中去。
编译型、解释型语言
编译型语言
需要通过编译器将源代码编译成机器码,之后才能执行的语言。一般需经过编译、链接这两个步骤。编译时把源代码编译成机器码,链接时把各个模块的机器码和依赖库串联起来生成可执行文件。
优点: 编译一次,运行时不需要编译,所以执行效率高,可以脱离语言环境独立运行(因为已经编译成了基于此机器系统的机器指令码)。大部分软件产品都是以目标程序形式发行给用户,不仅便于直接执行,而且又使得他人难以盗用其中的技术。
缺点: 编译之后如果需要修改则需要再次编译,由于编译执行的语言直接跟CPU的指令集打交道,具有很强的指令依赖性和系统依赖性,因此在不同操作系统之间移植会出现问题,需要根据运行的操作系统环境编译不同的可执行文件。
代表语言: C、C++、Pascal、Object-C
解释型语言
解释型语言的程序不需要编译,相比编译型语言省了道工序,解释型语言在运行程序时才逐行进行翻译。(边执行边翻译)
优点: 有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点: 每次运行的时候都要解释一遍,因此运行速度会稍慢。
代表语言: JavaScript、Python、Erlang、PHP、Perl、Ruby
脚本语言是解释型语言。
混合型语言
混合型语言在编译的时候不是直接编译成机器码,而是中间码。
例如java将程序翻译成一种中间代码字节码,可以被java解释器解释的独立于平台的代码。通过解释器,每条java字节指令被分析,然后运行在计算机上。只需编译一次,程序运行时解释执行。
可以把java字节码看作运行在java虚拟机上的机器代码指令。每种java解释器,不管是java 开发工具还是可以运行java小应用程序的web浏览器,都是一种java VM的实例,java VM也可以由硬件实现。
我们都知道java语言一个非常重要的特点是与平台无关性,而java VM是实现这一特点的关键。
GDB调试工具
使用GDB调试可执行程序,需要在程序编译时使用带-g的参数。
gcc -g test.c -o test
# 调试,会出现以下提示
gdb test
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/test...done.
(gdb)
堆和栈的区别
内存分配
一个由C/C++编译的程序占用的内存分为以下几个部分:
- 栈区stack:由编译器自动分配释放,存放函数的参数值,局部变量等,其操作方式类似于数据结构中的栈。简单来说就是程序运行而临时占用的区域空间。
- 堆区heap:一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。与数据结构的堆是两回事。分配方式类似于链表。
- 全局区(静态区)static:全局变量和静态变量的存储是放在一起的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域,程序结束后由系统释放。
- 文字常量区:常量字符串就是存放在这里。程序结束后由系统释放。
- 程序代码区:存放在函数体的二进制代码。
int a = 0; // 全局初始化区
char *p1; // 全局未初始化区
main()
{
int b; // 栈
char s[] = "abc"; // 栈
char *p2; // 栈
char *p3 = "123456"; // 123456/0在常量区,p3在栈上。
static int c = 0; // 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
p3 = new char[10];
// p1p2p3分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); // 123456/0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方.
}
堆栈内存模型
1. 堆
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。
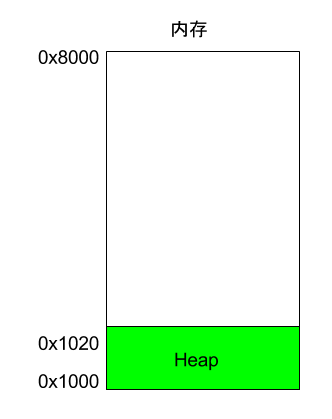
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
2. 栈
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
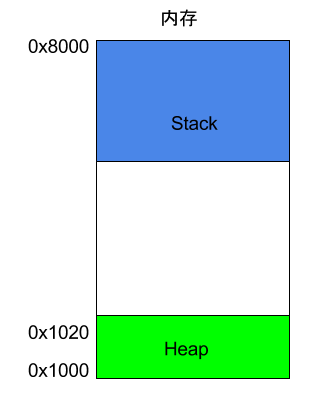
例如:
int main() {
int a = 2;
int b = 3;
}
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
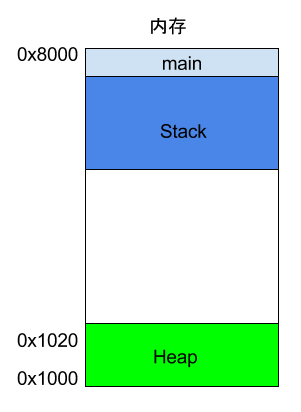
如果函数内部调用了其他函数,会发生什么情况?
int main() {
int a = 2;
int b = 3;
return add_a_and_b(a, b);
}
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
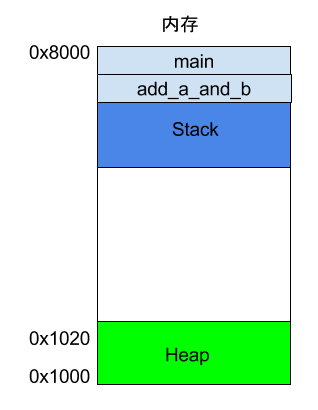
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",栈的回收叫做"出栈"。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
memset
包含在头文件string.h中
int a[100];
memset(a, 0, sizeof(int));
memset是按照一个字节字节进行赋值,如果memset(a, 1, sizeof(int)),那么数组中每个数都会为16843009 = 00000001000000010000000100000001。
namespace和头文件
namespace name{
//variables, functions, classes
}
name是命名空间的名字,它里面可以包含变量、函数、类、typedef、#define 等,最后由{ }包围。
::是一个新符号,称为域解析操作符,在C++中用来指明要使用的命名空间。
using Li::fp;
using std;
stdio.h、stdlib.h、string.h 等都是C语言的头文件,C++以开始也在用,后来 C++ 引入了命名空间的概念,计划重新编写库,将类、函数、宏等都统一纳入一个命名空间,这个命名空间的名字就是std。std 是 standard 的缩写,意思是“标准命名空间”。
后来C++开发了一些新的库,例如iostream,去掉了.h,对C语言中的库文件改写成stdio.h->cstdio。
C++在include和使用非.h头文件中的函数变量时,必须指定namespace,因为这些头文件中可能不止一个namespace。
缓冲区问题
输入输出不直接将信息放到指定地点,而是放到缓冲区,刷新缓冲区时才将这些信息输入、输出到指定位置。
缓冲区是内存空间的一部分,在内存中预留了一定的空间,用来暂存输入输出等I/O操作的一些数据,这些预留的空间就是缓冲区。
对于C/C++而言,cin,scanf,getchar等输入函数读取数据时,并不会直接从键盘上读取,而是从输入缓冲区中读取,即遵循一个过程:cin <- 输入缓冲区 <- 键盘。
同样的的cout,printf,putchar等输出函数在输出数据时,不会直接输出到屏幕中,而是先放入输出缓冲区,然后再输出到显示设备。
缓冲区的作用:
减少CPU对I/O设备的读写次数。
缓冲区的类型:
- 全缓冲:只有在缓冲区被填满之后才会进行I/O操作;最典型的全缓冲就是对磁盘文件的读写;
- 行缓冲;只有在输入或者是输出中遇到换行符的时候才会进行I/O操作;这忠允许我们一次写一个字符,但是只有在写完一行之后才做I/O操作。一般来说,标准输入流(
stdin)和标准输出流(stdout)是行缓冲。 - 无缓冲;标准I/O不缓存字符;其中表现最明显的就是标准错误输出流(
stderr),这使得出错信息尽快的返回给用户。
缓冲区操作函数(C语言):
- 标准输出函数:
printf、puts、putchar等。 - 标准输入函数:
scanf、gets、getchar等。 IO_FILE:fopen、fwrite、fread、fseek等
fflush函数的作用是清除缓冲区中的内容:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int a, b;
scanf("%d", &a);
b = getchar();
prinft("%d %p", a, b);
return 0;
}
// 123↓
// 123 0xa
#include <stdio.h>
#include <stdlib.h>
int main()
{
int a, b;
scanf("%d", &a);
fflush(stdin); // 清除标准输入流缓冲区
b = getchar();
prinft("%d %p", a, b);
return 0;
}
// 123↓c↓
// 123 0x63
const char *p 和 char * const p 的区别
const char *p; // 声明一个指向字符或字符串常量的指针(p所指向的内容不可修改)
char const *p;// 同上
char * const p;//声明一个指向字符或字符串的指针常量,即不可以修改p的值,也就是地址无法修改。
cin和cout
cout << "string...";
其中cout是一个预定义在iostream中的对象,<<是运算符重载,表示插入运算符,将后面的字符插入到输出流当中。
endl也是预定义在iostream中的。
cin是istream类的一个对象,cout是ostream类的一个对象。
extern istream cin; /// Linked to standard input
extern ostream cout; /// Linked to standard output
getline(cin, str); // getline不是一个类函数,将cin作为函数,表示从哪里去查找输入
cin.getline(char*, legth); // cin对象的getline函数没有处理string类的能力
函数原型和函数定义:‘
函数原型之于函数类似于变量声明之于变量,double sqrt(double);
函数原型只描述函数接口,包含参数和返回信息。
函数定义包含了编译代码。
库文件包含了函数编译代码,而头文件中则包含了原型。对于库函数,在使用之前需要提供其原型,通常把原型放到main()之前。
.h和.c的区别
要理解.c文件与.h文件有什么不同之处,首先需要弄明白编译器的工作过程,一般说来编译器会做以下几个过程:
- 预处理阶段(#开头的语句是预处理指令,其实预编译操作就是简单的文本转换)
- 词法与语法分析阶段
- 编译阶段,首先编译成纯汇编语句,再将之汇编成跟CPU相关的二进制码,生成各个目标文件
- 连接阶段,将各个目标文件中的各段代码进行绝对地址定位,生成跟特定平台相关的可执行文件,当然,最后还可以用objcopy生成纯二进制码,也就是去掉了文件格式信息
一般.h文件是写一些常量、变量、函数以及类的声明,而在.c/.cpp中对他们进行定义,一般需要加上预编译语句:
#ifndef CIRCLE_H
#define CIRCLE_H
//你的代码
#endif
.c/.cpp文件主要写实现头文件中已经声明的那些函数的具体代码。需要注意的是,开头必须#include一下实现的头文件,以及要用到的头文件。
.h文件叫作头文件,它是不能编译的,#include指令叫作预编译指令,可以理解成在真正编译前,把所有.h文件中的代码替换到头部。所以不建议在.h中声明变量,因为一个.h可能被多个.c文件引用,那么会出现重复定义。
一般.h文件和.c/cpp文件的文件名一致,可以方便知道谁和谁是一个模块,当然一个.h和.c之间可以没有任何关系。
从C编译器角度看,.h和.c皆是浮云,就是改名为.txt、.doc也没有大的分别。换句话说,就是.h和.c没啥必然联系。.h中一般放的是同名.c文件中定义的变量、数组、函数的声明,需要让.c外部使用的声明。这个声明有啥用?只是让需要用这些声明的地方方便引用。因为#include "xx.h" 这个宏其实际意思就是把当前这一行删掉,把xx.h 中的内容原封不动的插入在当前行的位置。由于想写这些函数声明的地方非常多(每一个调用xx.c 中函数的地方,都要在使用前声明一下子),所以用#include "xx.h" 这个宏就简化了许多行代码——让预处理器自己替换好了。也就是说,xx.h 其实只是让需要写xx.c 中函数声明的地方调用(可以少写几行字),至于include 这个.h 文件是谁,是.h 还是.c,还是与这个.h 同名的.c,都没有任何必然关系。
extern关键字
在一个.c文件中可以使用extern关键引用其它.c文件中声明的的变量函数..
extern int a; // 声明一个全局变量 a
int a; // 定义一个全局变量 a
extern int a = 0; // 定义一个全局变量 a 并给初值
int a = 0; // 定义一个全局变量 a, 并给初值
第四个等于第三个,都是定义一个可以被外部使用的全局变量,并给初值。
定义只能出现在一处,不管是int a;还是extern int a=0;还是int a=0;都只能出现一次,而声明extern int a可以出现很多次。
当要引用一个全局变量时,必须要声明。
有好的用法:
// a.c
#include<stdio.h>
int x = 5;
int fun(int a, int b)
{
return a + b;
}
// a.h
extern int x;
extern int fun();
// b.c
#include<stdio.h>
#include "a.h"
int main()
{
printf("%d", x);
printf("%d", fun(1,2));
return 0;
}
预编译指令
预编译指令主要作用是通过内建功能堆一个资源进行等价替换,最常见的有:
- 文件包含
#include主要是做为文件的引用组合源程序正文。
- #include
//标准库头文件 - #include <iostream.h> //旧式的标准库头文件
- #include "io.h" //用户自定义的头文件,对于#include <io.h> ,编译器从标准库路径开始搜索,对于#include "io.h" ,编译器从用户的工作路径开始搜索
- #include "../file.h" //UNIX下的父目录下的头文件
- #include "/usr/local/file.h" //UNIX下的完整路径
- #include "..\file.h" //Dos下的父目录下的头文件
- #include "\usr\local\file.h" //Dos下的完整路径
- 条件编译
#if #ifndef #ifdef #endif #undef主要是进行编译时进行有选择的挑选,注释掉一些指定的代码,以达到版本控制、防止对文件重复包含的功能。
#define 定义一个预处理宏
#undef 取消宏的定义
#if 编译预处理中的条件命令,相当于C语法中的if语句
#ifdef 判断某个宏是否被定义,若已定义,执行随后的语句
#ifndef 与#ifdef相反,判断某个宏是否未被定义
#elif 若#if, #ifdef, #ifndef或前面的#elif条件不满足,则执行#elif之后的语句,相当于C语法中的else-if
#else 与#if, #ifdef, #ifndef对应, 若这些条件不满足,则执行#else之后的语句,相当于C语法中的else
#endif #if, #ifdef, #ifndef这些条件命令的结束标志.
#defined 与#if, #elif配合使用,判断某个宏是否被定义
- 布局控制
#progma主要功能时为编译程序提供非常规的控制流信息。 - 宏替换
浮点数的存储方式

decimal.Decimal
python中的decimal.Decimal类型可以非常精确地存储在计算机中,其优于float类型。
用法:
from decimal import Decimal
# 字符串/浮点数转换为Decimal
Decimal('1.11')
# >>Decimal('1.11')
Decimal(1.11)
# >>Decimal('1.1100000000000000976996261670137755572795867919921875')
# 四舍五入
Decimal('50.5679').quantize(Decimal('0.00'))
# >>Decimal('50.57')
# Decimal 结果转化为string
str(Decimal('3.40').quantize(Decimal('0.0')))
# >>'3.4'
将浮点数以二进制输出:
#include <stdio.h>
int main(void)
{
float fnum = 1;
int i;
int * p = (int *)&fnum;//定义一个指向fnum的指针
int x=0;//设置flag变量
while (fnum != 0)//以0作为输入结束标志
{
printf("input a num: ");
x=scanf("%f", &fnum);
if(!x)//判断是否输入成功
{
printf("wrong\n");
fflush(stdin);//清空输入流,不然会死循环
continue;
}
for (i = 31; i >= 0; i--)
{
/*将1左移i位,通过与运算判断第i位是否为1*/
printf("%d", (*p & (1 << i) ? 1: 0));
/*控制空格输入*/
if(i==31||i==23)
printf(" ");
if(i==27||i==19||i==15||i==11||i==7||i==3)
printf(" ");
}
printf("\n");
}
return 0;
}
实现按照map的value排序
//功能:输入单词,统计单词出现次数并按照单词出现次数从多到少排序
#include <iostream>
#include <cstdlib>
#include <map>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
int cmp(const pair<string, int>& x, const pair<string, int>& y)
{
return x.second > y.second;
}
void sortMapByValue(map<string, int>& tMap,vector<pair<string, int> >& tVector)
{
for (map<string, int>::iterator curr = tMap.begin(); curr != tMap.end(); curr++)
tVector.push_back(make_pair(curr->first, curr->second));
sort(tVector.begin(), tVector.end(), cmp);
}
int main()
{
map<string, int> tMap;
string word;
while (cin >> word)
{
pair<map<string,int>::iterator,bool> ret = tMap.insert(make_pair(word, 1));
if (!ret.second)
++ret.first->second;
}
vector<pair<string,int>> tVector;
sortMapByValue(tMap,tVector);
for(int i=0;i<tVector.size();i++)
cout<<tVector[i].first<<": "<<tVector[i].second<<endl;
system("pause");
return 0;
}