vearch基于Faiss实现,但 Faiss 本身只是一个能够单机运行的支持各种向量检索模型的机器学习算法基础库,不支持分布式、实时索引和检索,同时也不支持标量字段的存储和索引等等。
主要应用场景:
- 图像/视频/音频检索和去重;
- 安防领域视频智能监控;
- 文本相似度计算;
- 推荐,搜索召回及排序。
CASE
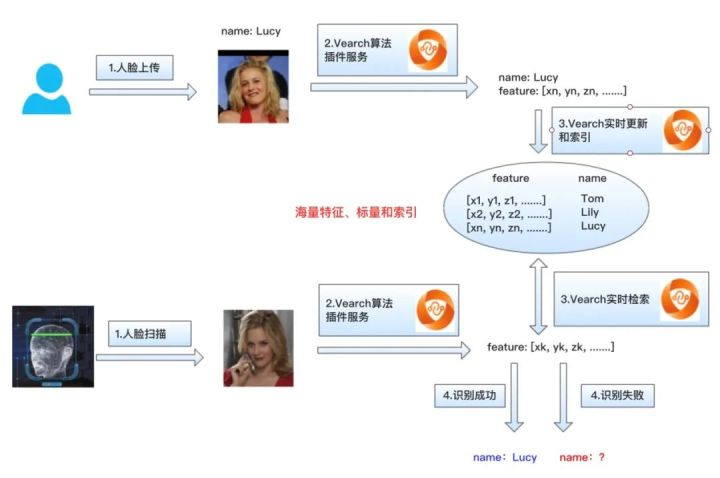
1. 人脸数据查找索引
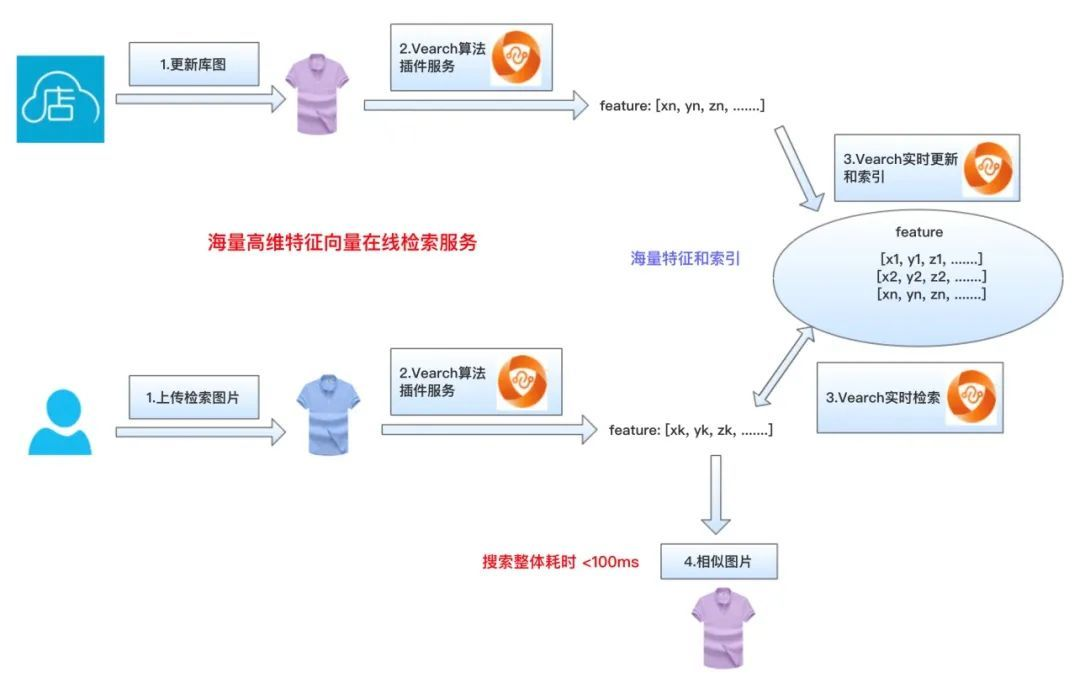
2. 在线相似性图片搜索
例如电商平台的搜同款。
vearch对外提供Restful API,方便对表及数据进行管理。
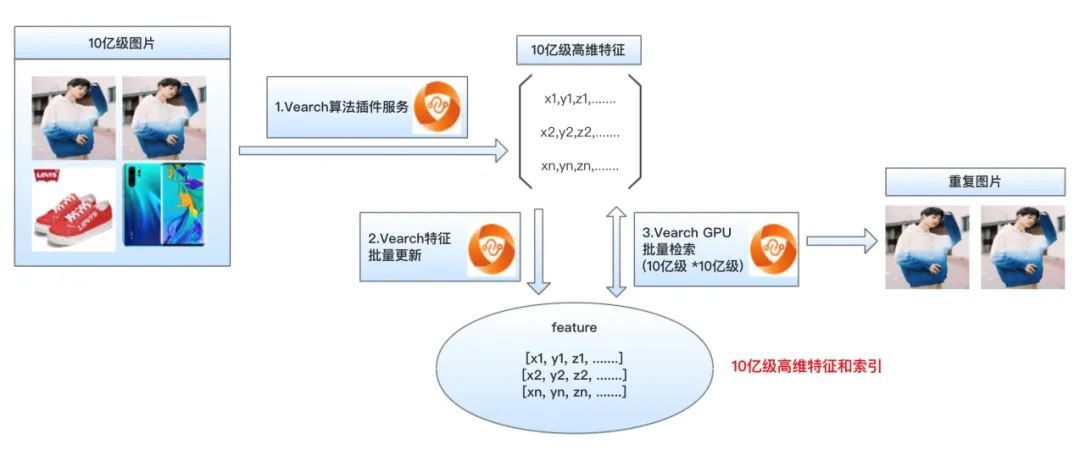
3. 图片去重
4. 搜索/推荐系统的召回
将数据的各种特征embedding成向量后,利用向量相似性检索做召回。
使用
示例:
查询
{
"query": {
"sum": [{ // 查询特征,支持多个
"field": "field_name", // 指定创建表时特征字段的名称
"feature": [0.1, 0.2, 0.3, 0.4, 0.5], // 传递特征,维数和定义表结构时维数必须相同
"min_score": 0.9, // 指定返回结果中分值必须大于等于0.9,两个向量计算结果相似度在0-1之间,min_score可以指定返回结果分值最小值,max_score可以指定最大值
"boost": 0.5 // boost指定相似度的权重,比如两个向量相似度分值是0.7,boost设置成0.5之后,返回的结果中会将分值0.7乘以0.5即0.35。
}],
"filter": [{ // 过滤条件(数值、标签过滤),支持多个
"range": {
"field_name": {
"gte": 160,
"lte": 180
}
}
// range 指定使用数值字段integer/float 过滤, filed_name是数值字段名称,
// gte、lte指定范围, lte 小于等于, gte大于等于,若使用等值过滤,lte和gte设置相同的值。
// 上述示例表示查询field_name字段大于等于160小于等于180区间的值
},
{
"term": {
"field_name": ["100", "200", "300"],
"operator": "or"
}
// term 使用标签过滤, field_name是定义的标签字段,允许使用多个值过滤,
// 可以求交“operator”: “or” , 求并: “operator”: “and”,上述示例表示查询field_name字段值是”100”、”200” 或”300”的值。
}]
},
"direct_search_type": 0, // direct_search_type 指定查询类型,0代表若特征已经创建索引则使用索引,若没有创建则暴力搜索; -1 代表只使用索引进行搜索, 1代表不使用索引只进行暴力搜索。默认值是0。
"quick": false, // quick 搜索结果默认将PQ召回向量进行计算和精排,为了加快服务端处理速度设置成true可以指定只召回,不做计算和精排。
"vector_value": false, // vector_value为了减小网络开销,搜索结果中默认不包含特征数据只包含标量信息字段,设置成true指定返回结果中包含原始特征数据。
"online_log_level": "debug",
"size": 10 // 返回结果数量
}